


Наявні мультимодальні моделі досі не здатні виконувати завдання, що потребують інтерактивного планування та орієнтації в динамічному середовищі, пише Успіх in UA.
Такого висновку дійшли дослідники з Принстонського університету у роботі VideoGameBench, повідомляє forklog.com.ua.
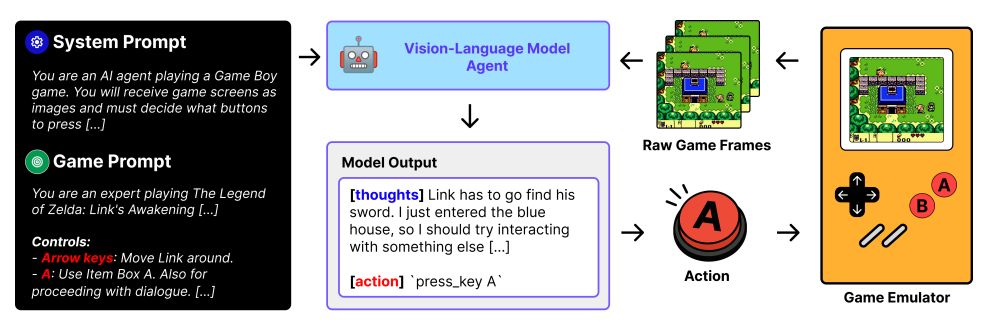
Науковці перевірили моделі Gemini 2.5 Pro, GPT-4o, LLaMa 4, Gemini 2.0 Flash і Claude 3.7 Sonnet у 10 популярних 2D-іграх кінця 90-х — від Super Mario до Age of Empires. Умови: доступ лише до відеопотоку гри та короткий опис управління й цілі.
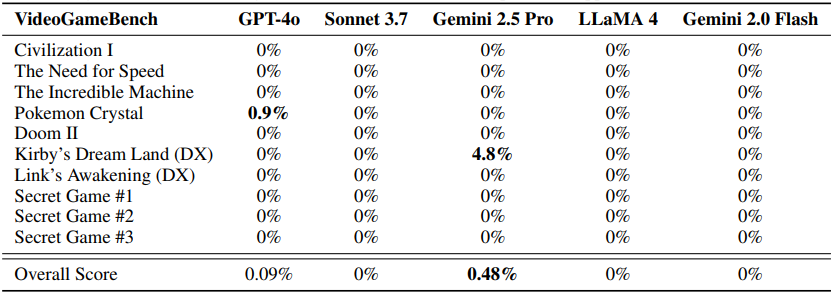
Найкращий результат у реальному часі — лише 0,48% успішності, показаний Gemini 2.5 Pro. У спрощеному режимі Lite, де гра зупиняється перед кожною дією, результат трохи вищий — 1,6%.
На відміну від текстових завдань, ігри вимагають не лише розпізнавання зображення, а й швидких рішень, просторової пам’яті, довгострокового планування та адаптації до мінливих умов. Затримки інференсу навіть у найсучасніших VLM-моделях не дозволяють їм діяти в реальному часі, особливо в аркадних або стратегічних тайтлах.
«Моделі не можуть зрозуміти просту інструкцію на кшталт “увімкни млин”, навіть маючи підказки на екрані», — зазначають автори дослідження.
Читайте також: Науковці назвали дату комп’ютерного “апокаліпсису”
За їх словами, навіть базова логіка ігрового світу (наприклад те, що вода потрібна для виробництва їжі) виявилася надто складною для сучасних VLM.



Залишити відповідь